System Design 101
Basic System Design concepts every Software Engineer should understand

All my interviews are wrapped in a little story. And in almost all of them I end up doing a simple question:
Why is it so important to design our services so they have no state? Specially if they are running somewhere on a server.
It is surprising how many people get it wrong. And when they get it wrong, I do a follow up question:
What is a Load Balancer?
To which almost everybody answers that DevOps/SRE is not their field. This is wrong!
Every Software Engineer (I don't care if you call yourself developer, programmer or unicorn) should understand at least the basics of System Design, no matter their seniority or if their specialty is frontend, backend, mobile, productivity tools or no code.
- Mostly because it is essential to have a holistic and systemic understanding of how different services and applications interact.
- Because the way your infrastructure is set up affects your code. Obviously.
- And also because it is not that difficult. You don't have to know how to set up a Load Balancer but it is important to understand what it is, why you need one and when to use it.
This is the first post of a series (probably three) that cover the basics of System Design. I will not enter in details because it would require to write a whole book about each topic. However, I will provide many resources for you to further read and investigate.
A client, a server and a database walk into a coffee shop
The most typical setup that you will find out there is a frontend application (let's say it uses React) that talks to a backend service (let's say it's a Spring application written in Kotlin that serves a REST API and runs in a Docker container) which in turn is connected to a database (let's say PostgreSQL).
{kind=link}
But this representation of the system is incomplete at most. If not totally unacurrate. Thruth being told, there is not just one instance of the frontend application. That would be terrible. Instead, each client runs one on their own device. Desktop or mobile. Each one with their own connectivity conditions using different browsers. And obviously, you can't ignore DNS.
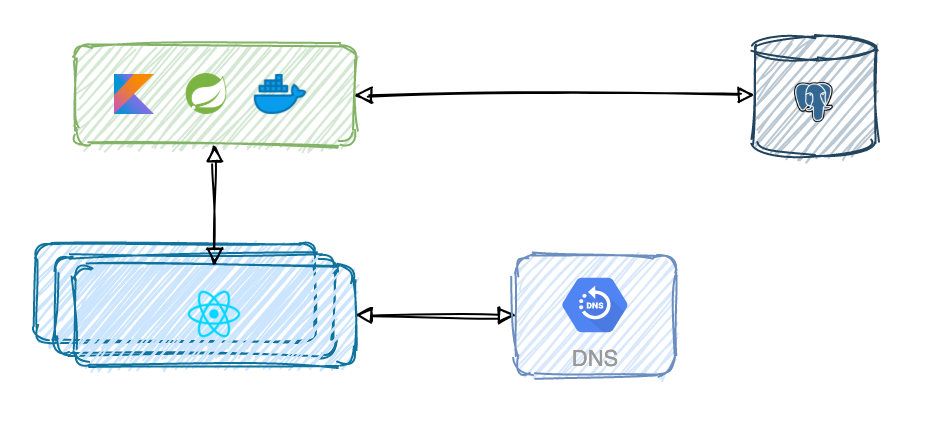
This is more accurate but it's still far from reality. At least on the frontend side. So let's talk about what happens when you type a url into a browser and press Enter.
So you press Enter
Nowadays people just connect their GitHub repository to Netlify or a similar service and they're happy. But let's take a step back and acknowledge that all HTML, CSS, JS files and the other static assets of a web page need to be stored somewhere on the dark corners of the Internet. Netlify takes care of this and much more but not so long ago people needed to build their React application themselves and upload the content to a service like AWS S3.
But storing that content is not everything. It needs to be served somehow to the users and it turns out CDNs are very good at that.
So here is how it goes step by step:
- The browser asks the DNS for the corresponding IP address of the url. That IP address corresponds to the CDN (maybe AWS Cloudfront).
- The browser asks for the content to the CDN. If the CDN doesn't have the content in the cache, the CDN requests it from the storage (maybe AWS S3).
- The storage returns the content to the CDN server. It sometimes includes an HTTP header called Time-to-Live (TTL) which describes how long the content is cached.
- The CDN catches the content and returns it to the browser. The content remains cached in the CDN until the TTL expires.
- When another browser asks for the content, the CDN returns it directly until the TTL expires.

Today you could probably skip all this but you will still find a lot of applications out there that use this setup (probably most of them). So here is a post explaining how to host on AWS S3 with CloudFront as a CDN and here is another one explaining how to migrate the whole thing to Netlify. Your welcome.
Unless the web page has like a huge lot of traffic you won't have to worry about scalability issues for some time. But what happens with the backend?
Put a Load Balancer in your life
You can't controll where the different instances of the frontend application will run. But with backend services is different. Not only can you control how many instances of the service are running at any time. But you can also control the configuration of the server (like RAM or CPU) in which each instance is running.
You can scale the service vertically or scale it up. Mostly when traffic is low. Just add more memory and/or CPU to the server. However, this is naturally limited, and it increases costs very quickly. Memory and CPU are naturally expensive resources.
Horizontal scaling or scale out is more desirable for large scale services. It just means you can spin up as many instances as you want. But this solution comes with a couple of problems. Don't worry, they can be solved. How can you have a single entry point so the design is not leaked to the outside world? How can you balance the traffic load between all the instances? You're right. Using a Load Balancer.
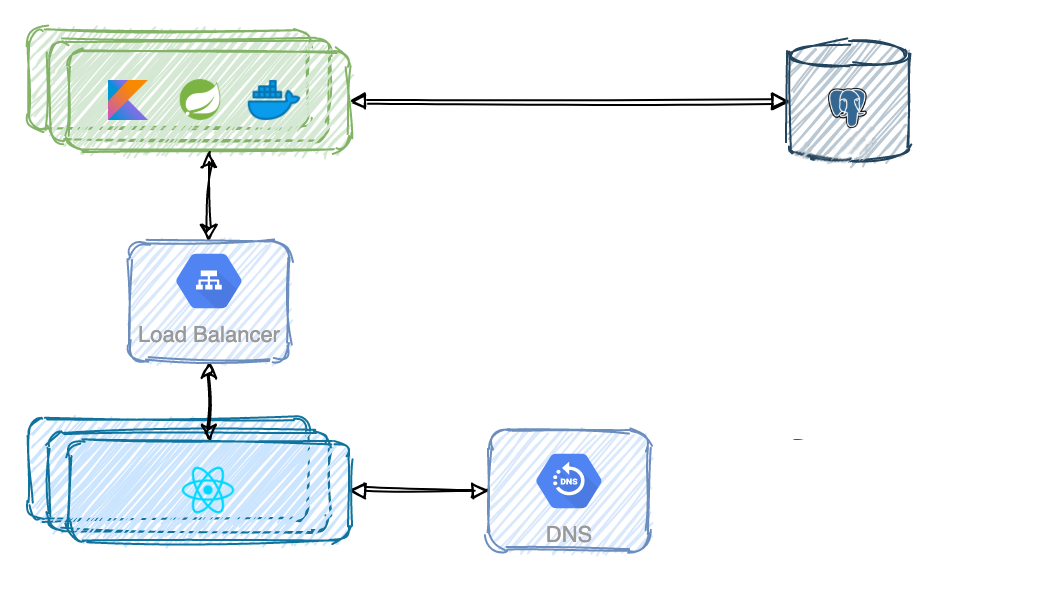
With this setup, the backend services are unreachable directly by clients anymore. They connect to the public IP of the Load Balancer which evenly distributes incomming traffic and communicates internally through private IPs.
Horizontal scaling comes with additional benefits. If one instance goes offline, traffic will be routed to the remaining instances. If traffic grows rapidly you can automatically spin up as many instances as needed and shut them down afterwards to control costs.
And here it is the initial question.
Why is it so important to design our services so they have no state? Specially if they are running somewhere on a server.
Assuming horizontal scaling, there is no guarantee a client will hit the same instance of the service twice in row. It's true that depending on the algorithm of the Load Balancer you can have some consistency. But what happens if an instance crashes completely? State would be lost forever. That's why state is stored in a database, which may at some point become a problem because there is only one instance of it. And it'll probably be your next bottleneck.
One of the two hard things
There are only two hard things in Computer Science: cache invalidation and naming things. -- Phil Karlton
You can remove some load from the database by using a cache, which is a temporary data store layer, such as Redis or Memcached. It usually stores the result of expensive responses or frequently accessed data. It is much faster than the database because it stores the data in memory. You must be careful though: if a cache server restarts, all the data is lost.
How it works?
- After receiving a request, the backend server first checks if the cache has the available response.
- If it hasn't, it queries the database, stores the response in cache, and sends it back to the client.
- Next time a client asks for the same data, it is returned directly from the cache without quering the database.
{kind=link}
You better use cache when data is read frequently but modified infrequently. And don't forget to implement an expiration policy. Once the data is expired, it is removed from the cache. The expiration policy helps to keep the cache data in sync with the database but it does not solve the consistency problem. Invalidating cache when needed is challenging and is not a topic I'm willing to write about now.
The clone wars
Cache is good and all that but at some point it won't be enough. The database is still a single instance. A single point of failure and a bottleneck.
Read operations are usually more frequent than write operations. So you can use replication which is a technique for managing multiple instances of a database, usually with a principal/secondary relationship between the original and the copies. The principal database generally supports only write operations while the copies only support read operations.
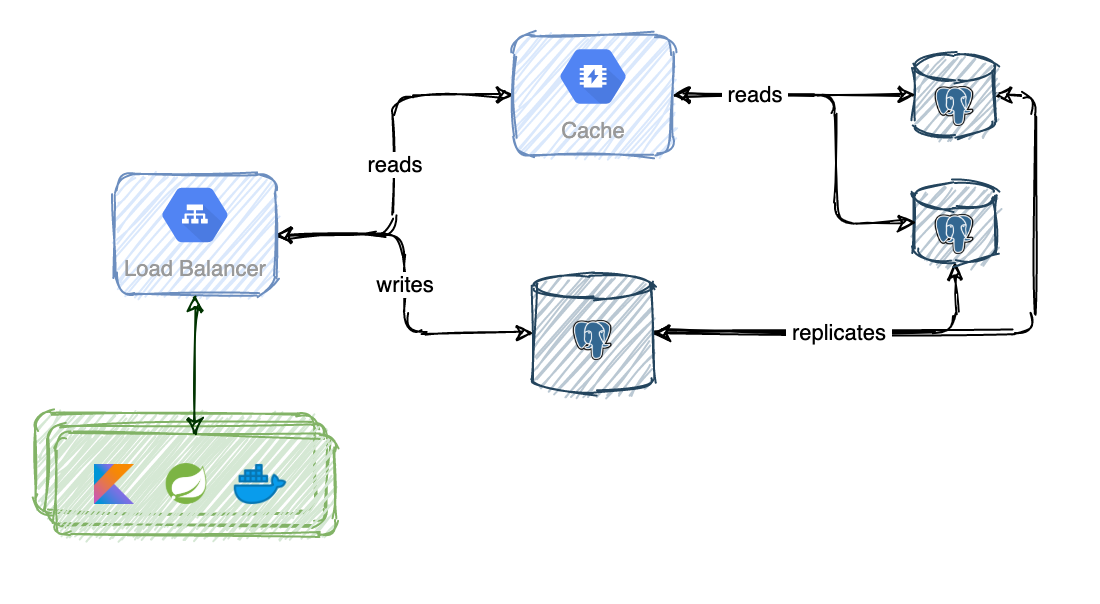
Replication has multiple advantages like better performance, reliability and high availability. The read operations are distributed across the secondary databases, data is never lost because it is replicated across multiple locations and even if one secondary database goes offline you can still access data from other locations.
If all the secondary databases go offline, read operations will be directed to the principal database temporarily. Whenever a secondary database is up and running, read operations will again be redirected to them.
If the principal database goes offline, a secondary database will be promoted to be the new principal database. A new instance will replace the old secondary database. This is more difficult than it sounds because in real life data may or may not be syncronized.
If all the database instances, principal and secondary, go offline, you have a huge problem.
Replication is just one of many techniques for scaling the database horizontally. Sharding is another one but I will talk about it in another post.
The magic always happens asynchronous
Some of the tasks your services execute, like sending a notification or processing a photo, don't need to happen right away. They can be executed asynchronously. However, the instructions for knowing what task to execute need to be stored somewhere until a service is ready for executing it. For that you can use a task Queue also called a message Queue. In reality there are differences between a task Queue and a message Queue but I'm going to ignore them for now. You may have heard of RabittMQ, AWS SQS or Celery.
{kind=link}
The basic architecture of a Queue is simple. Some services, called producers or publishers, create messages and publish them to the Queue. Other services, called consumers or subscribers, connect to the Queue and consume the messages one by one to perform the needed tasks.
There are only two hard problems in distributed systems: 2. Exactly-once delivery 1. Guaranteed order of messages 2. Exactly-once delivery.
Using e message Queue comes with its own problems. It is difficult to ensure that a message will be consumed exactly once. It is equally difficult to ensure all the messages will be consumed in the desired order.
A new beginning
Here is a more complete and holistic view of the system and how the different services interact. In terms of scalability, your product needs to be very successful so you need more than this. But I haven't discussed yet authentication, security or rate limiters.
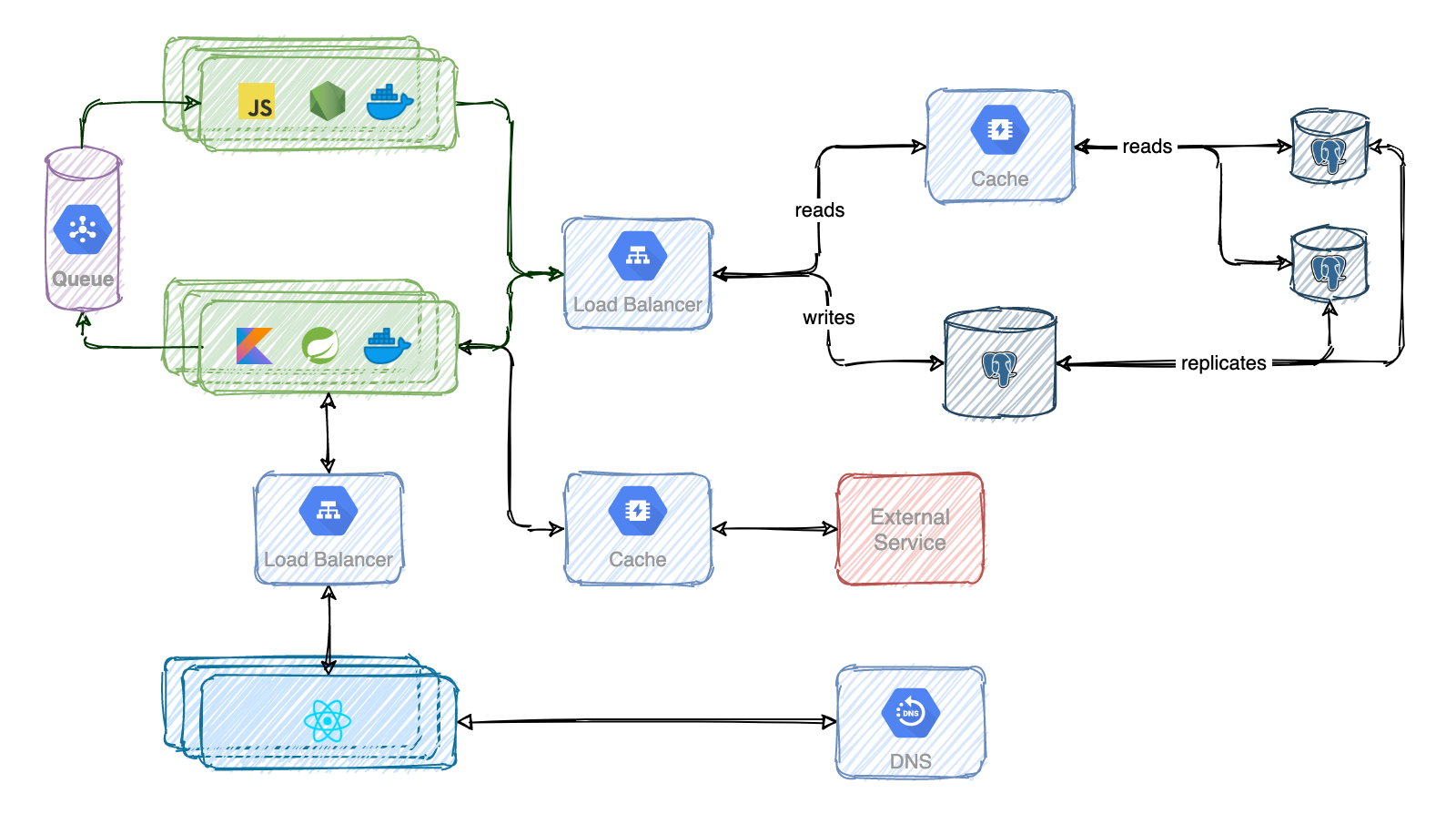
In the diagram you can see a bunch of monoliths: one for the frontend and other for the backend. Read the second post in which I talk about the implications of having multiple services talking to each other when breaking the monoliths, backends for frontend, microfrontends or server side rendering. In next posts I will cover other topics such as multiple data centers, virtual private networks or sharding.